We Are Writing Python Polars: The Definitive Guide

Jun 6, 2023 • 16 min read.
I’m excited to announce, on my 40th birthday no less, that I’ll be writing another book. But this time I won’t be alone. Thijs Nieuwdorp is joining me in this adventure that we’ve dubbed Python Polars: The Definitive Guide. We expect our upcoming O’Reilly title to be about 400 pages and to hit the shelves in Q3 2024. Fun fact: Thijs and I are colleagues at Xomnia, the very birthplace of Polars.

A big thank you to Aaron Black for helping us to seal this deal. We’re looking forward to work again with Sarah Grey. Sarah was also the development editor for the second edition of Data Science at the Command Line.
Stay up to date
We’ll share regular updates via Twitter (JJ, TN) and LinkedIn (JJ, TN). Sign up for my newsletter if you want to receive an email when the book is out:
If want to help us spread the word, you can like or share this announcement on Twitter and LinkedIn. Your help is much appreciated.
About Polars
Polars is a highly performant DataFrame library for manipulating structured data. The core is written in Rust, and the library is officially available in Python, Rust, NodeJS, R, and SQL. Its three key selling points are:
- Record-breaking speed on common DataFrame operations
- Processing of larger than memory datasets
- Explicit, concise, and flexible syntax
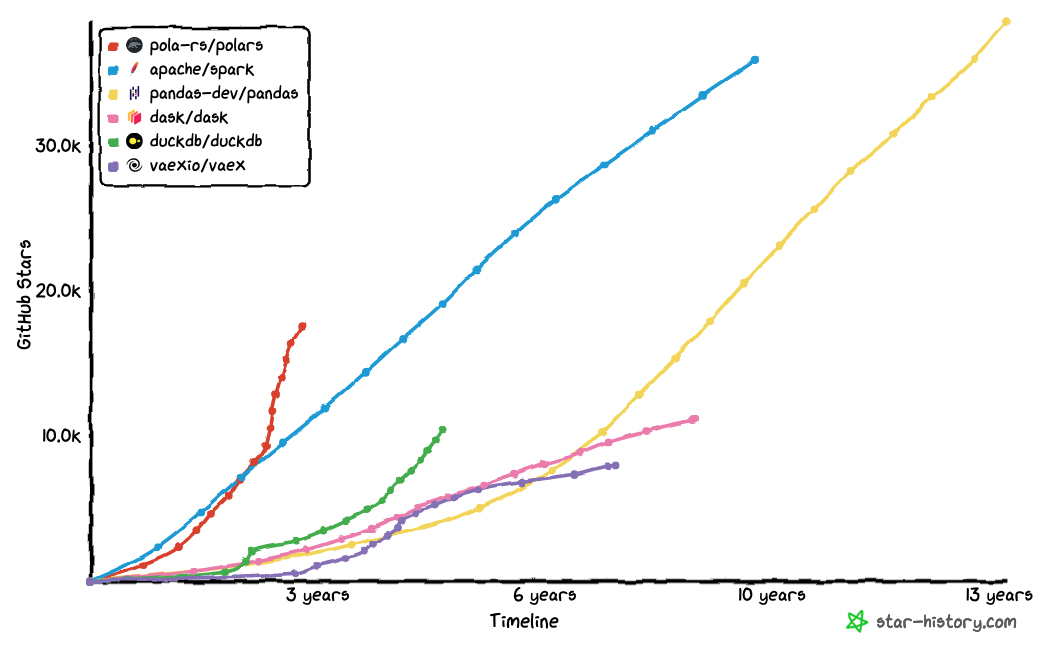
For more information see the official Polars website and the Polars GitHub repository.
Foreword by Ritchie Vink
Ritchie Vink, the creator of Polars, has kindly agreed to write the foreword. We couldn’t wish for a bigger endorsement. Ritchie has no interest in writing a book himself as he wants to focus all his time and attention on developing Polars. He’s very excited that Thijs and I will write this book and he’s happy to provide assistance throughout the writing process.
Tentative description
Get ready to speed up your data analysis and start working with larger-than-memory datasets. Polars offers a blazingly fast, multi-threaded, elegant API for data loading, manipulation, and processing. Authors Jeroen Janssens and Thijs Nieuwdorp walk you through every aspect of Python Polars as they tackle practical use cases using real-world datasets. You’ll not only learn the syntax, but also understand the underlying concepts. You don’t need to have any experience with Pandas or Spark, but if you do, this book will help you make a smooth transition.
With this definitive guide at your side, you’ll be able to:
- Process larger-than-memory datasets at record speed
- Apply the eager, lazy, and streaming APIs of Polars and decide when to use which
- Transition smoothly from Pandas or Spark to Polars
- Integrate Polars into your existing codebase
- Work with Arrow and Parquet to efficiently read and write data
- Translate complex ETL tasks into efficient and elegant queries
Tentative outline
We’re quite happy with this outline, but it’s definitely not set in stone. If you have any ideas don’t hesitate to reach out.
Part I: Getting Started
Chapter 1: Introducing Polars
The goal of this chapter is to get you excited about Polars as soon as possible, by discussing where it comes from, covering its unique features regarding speed and elegance, explaining how it fits into the bigger picture, and walking them through a case study on a real-world public dataset.
- Origin Story
- Polars Philosophy and Features
- Polars within the Bigger Ecosystem
- Why Focus on Python Polars?
- A Real-World Case Study
Chapter 2: First Steps
Once you’re excited, it’s important to get you on board, so you can
follow along and run the code samples themselves. The goal of this
chapter is to help you get set up, whether you’re installing Polars
using pip install, using it via our accompanying Docker image, or
compiling it from scratch.
- Installing Polars
- Using Polars in a Docker Container
- Compiling Polars from Scratch
- Importing Polars
- Configuring Polars
Chapter 3: Transitioning from Pandas or Spark to Polars
We expect many readers to have experience with Pandas or Spark. In this chapter we ensure that their transition to Polars is as smooth as possible by highlighting similarities and, more importantly, important differences between these tools.
- Similarities
- No Index and MultiIndex
- Numpy Versus Arrow Arrays
- Rows versus Columns
- Differences in Syntax
- Common Pitfalls To Avoid
Part II: Concepts and Syntax
This part forms the heart of the book. The goal is to explain all the functionality needed to analyze data efficiently and effectively. The chapters are meant to complement the online documentation. That means they will not be just a list of methods. Instead, we will use real-world public datasets, provide context, and explain the why and how behind an approach. If there are multiple approaches to accomplish a task, we will discuss the pros and cons of each.
Chapter 4: Data Types and Data Structures
The goal of this chapter is to introduce the fundamental data types and data structures. All functionality interacts with these, so it’s important to induce this at the beginning.
- Arrow Data Types
- Series
- DataFrame
- LazyFrame
Chapter 5: Eager, Lazy, and Streaming APIs
In this chapter we explain the different types of APIs Polars has to offer.
- Collecting
- Caching
- Performance Differences
- Functionality Differences
- When to use Which API?
Chapter 6: Reading and Writing Data
We want to encourage the reader to start working with their own data as soon as possible. In this chapter we demonstrate the various ways to read data into Polars and to write the result back.
- CSV
- Excel
- Parquet
- JSON
- Multiple Files
- Databases
- AWS
- Google BigQuery
Chapter 7: Expressions
The goal of this chapter is to introduce Expressions, which are what makes the Polars API so powerful and elegant. They play an essential role in the remaining chapters of Part II.
- Operators
- Composing Expressions
- Functions
- Type Casting
- Renaming
Chapter 8: Selecting and Creating Columns
The goal of this chapter is to explain how existing columns in a DataFrame can be rearranged or dropped and new columns can be created. We’re going to apply the various functions on real-world datasets.
- Selection Context
- Regular Expressions
.with_columns()and Relevant Expressions- Adding Row Counts
Chapter 9: Filtering and Sorting Rows
Whereas the previous chapter was about columns, this chapter is all about the rows in a DataFrame. How can rows be sorted or discarded based on some condition. Again, we’re going to demonstrate the various functions by using real-world datasets.
- Filtering Context
- Predicates
- Compound Predicates
- Sorting
- Sorting in a Selection Context
Chapter 10: Working with Special Data Types
There are certain data types that deserve special attention. This chapter covers how to deal with strings, categories, time series, columns that contain lists as values, and missing values.
- Strings
- Categories
- Temporal Data
- Lists
- Missing Values
Chapter 11: Summarizing and Aggregating
This chapter discusses how the reader can summarize and aggregate their data. There are various ways to do this, and it’s important to know when to use which.
- Groupby Context
.over()Expressions in Selection Context- Dynamic Grouping
- Rolling Aggregations
Chapter 12: Joining and Concatenating
Data often comes from multiple sources. In this chapter we explain different ways how these sources can be combined.
- Basic Joining
- Semi and Anti Joining
- Inexact Joining
- Vertical Concatenation
- Horizontal Concatenation
Chapter 13: Reshaping
The same values can be represented in a long or wide format (or something in between). This chapter covers different ways to reshape the data.
- Wide Versus Long DataFrames
- Pivot to Wider DataFrame
- Melt to Longer DataFrame
- Exploding
- Correlating
- Partition Into Multiple DataFrames
Part III: Advanced Topics
Chapter 14: Extending Polars
Sometimes you just need additional functionality and business logic in your data analysis. This chapter explains how to properly create User Defined Functions and extend the Polars data structures with additional expressions and methods so that the code remains fast and elegant.
- User Defined Functions
- Custom Expressions
- Custom Methods
Chapter 15: SQL with Polars
Polars allows you to apply SQL queries directly on DataFrames. If you already knows SQL, then that can be very useful. This chapter explains how to do that in Python and from the command line.
SELECTQueriesCREATEQueries- Common Table Expressions
- Command-Line Interface
Chapter 16: Debugging and Testing with Polars
When a data analysis has to be put in production, it’s important to be able to deal with exceptions and to add appropriate unit tests. This chapter explains how to debug and test your Polars code.
- Explaining Query Plans
- Using Polars in Unit Tests
- Polars Exceptions and Asserts
- Parametric Testing
Chapter 17: Polars Internals
In this chapter we take a look under the hood of Polars. If the reader understands what makes Polars fast, then they’ll be able to avoid writing code that slows it down.
- What Makes Polars so Fast?
- Query Optimization
- Multi-Threaded Computations
- SIMD Operations
Chapter 18: Integrating with Other Tools
Polars is part of a larger PyData ecosystem. Thanks to Apache Arrow, Polars is able to work together seamlessly with other tools. This chapter explains how to integrate Polars with those tools.
- Pandas
- PyArrow
- DuckDB
Would you like to receive an email whenever I have a new blog post, organize an event, or have an important announcement to make? Sign up to my newsletter: