Python workshops

In deze tweedaagse workshop helpen we je op weg om te leren programmeren in Python, een van de meest populaire talen voor scripts, productiesoftware en data science.
Aan de hand van realistische voorbeelden maak je kennis met verschillende fundamentele programmeerconcepten, zoals variabelen, functies en control flow. De workshop zal hands-on zijn, met uitdagende oefeningen. Uniek aan deze workshop is dat we JupyterLab gebruiken, een populaire omgeving om interactief code uit te voeren en data science te doen.
Deze workshop bereidt je niet alleen voor op meer geavanceerde Python workshops, maar biedt je ook een solide en betrouwbare basis voor jouw data science reis.
online of op locatie

Leer hoe je jouw data analyses kunt versnellen met Pandas, een Python pakket die speciaal is ontworpen voor het werken met middelgrote datasets. Samen met JupyterLab maakt het een handige omgeving voor interactieve data analyse mogelijk.
Pandas maakt deel uit van het zogenaamde PyData-ecosysteem, en in deze workshop beginnen we met het geven van een overzicht van PyData en leggen we uit waar Pandas staat en hoe het samenwerkt met andere pakketten zoals NumPy en Seaborn. Pandas introduceert een paar nieuwe datastructuren, met name het DataFrame, die essentieel zijn om te begrijpen hoe efficiënt met tabelgegevens kan worden gewerkt.
Pandas biedt veel functies, en in een dag, door een goede balans tussen presentatie en interactieve oefeningen, gaan we de belangrijkste behandelen, waaronder: importeren, filteren, groeperen, samenvoegen, verkennen en visualiseren van gegevens. Aan het einde van deze workshop begrijp je de grondbeginselen van Pandas, ben je je bewust van veelvoorkomende valkuilen en ben je klaar om je eigen analyses uit te voeren.
online of op locatie

Het internet is niet alleen een verzameling webpagina’s, het is een gigantische bron van interessante gegevens. Automatisch deze gegevens kunnen extraheren is een waardevolle vaardigheid. Het is zeker uitdagend, maar met de juiste kennis en tools kun je een schat aan informatie gebruiken voor je persoonlijke en professionele data science projecten.
Stel je voor dat je een webscraper bouwt die legaal informatie verzamelt over potentiële huizen om te kopen, een proces dat automatisch dat vervelende formulier invult om een rapport te downloaden, of een crawler die een bestaande dataset verrijkt met weersinformatie. In deze hands-on workshop leren we je hoe je dat kunt bereiken met Python en een handvol packages.
Je leert over de concepten die ten grondslag liggen aan HTML, CSS-selectors en HTTP-verzoeken; en hoe je deze kunt inspecteren met behulp van de ontwikkelaarstools van de browser. We laten je zien hoe je rommelige HTML kunt omzetten in gestructureerde datasets, hoe je de interactie met dynamische websites en formulieren kunt automatiseren en hoe je crawlers kunt opzetten die duizenden of miljoenen websites kunnen doorspitten. Door tal van oefeningen ben je in staat om deze nieuwe kennis in een mum van tijd toe te passen op je eigen projecten.
online of op locatie

Machine learning is een essentieel onderdeel geworden in veel applicaties en projecten waarbij data betrokken zijn. Met de kracht van Python en het scikit-leerpakket is dit spannende vakgebied niet langer exclusief voor grote bedrijven met uitgebreide onderzoeksteams. Als je Python gebruikt, zelfs als beginner, worden machine learning-toepassingen alleen beperkt door jouw verbeeldingskracht.
Tijdens deze workshop zullen we een hands-on benadering hanteren om te leren over machine learning algoritmen. Onderwerpen zijn onder meer: regressie, classificatie, outlier detectie, dimensionaliteitsreductie en clustering. Gedurende twee dagen zullen we verschillende algoritmen verkennen, zoals lineaire regressie, logistische regressie, random forests, neurale netwerken en nog veel meer.
Aan het einde van deze workshop zul je vol vertrouwen machine learning-algoritmen selecteren en gebruiken met behulp van Python en scikit-learn. Je hebt een beter begrip gekregen van de werking van de algoritmen en weet hoe je deze kunt gebruiken om waardevolle resultaten en inzichten te produceren.
online of op locatie

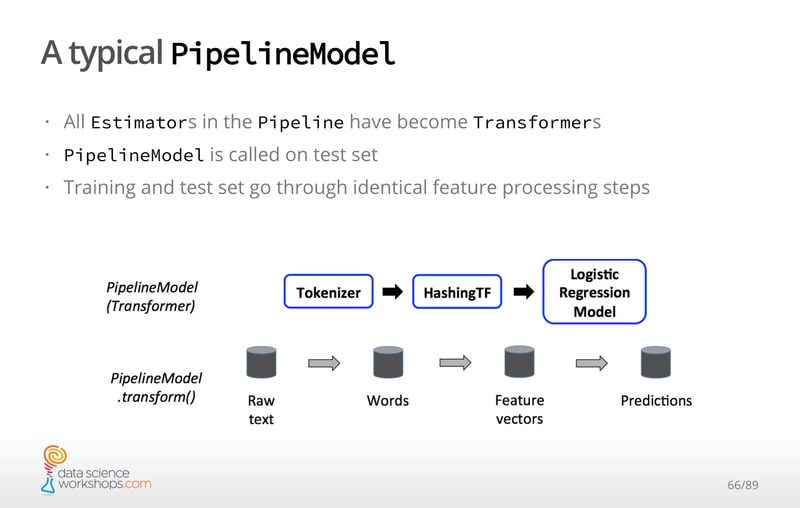
Apache Spark is een open source gedistribueerde engine voor het opvragen en verwerken van data. In deze driedaagse hands-on workshop leer je hoe je Spark vanuit Python (PySpark) kunt gebruiken om grote hoeveelheden data te verwerken.
Na een overzicht van de Spark architectuur, beginnen we met het manipuleren van Resilient Distributed Datasets (RDD’s) om vervolgens de overstap te maken naar Spark DataFrames. Het concept van lazy evaluation wordt in detail besproken en we demonstreren verschillende transformaties en acties die specifiek zijn voor RDD’s en DataFrames. Je leert hoe DataFrames kunnen worden gemanipuleerd met behulp van SQL query’s.
We laten je zien hoe je supervised machine learning algoritmen toepast, zoals lineaire regressie, logistische regressie, beslisbomen en random forests. Je leert ook over unsupervised machine learning algoritmen zoals PCA en K-means clustering.
Aan het einde van deze workshop heb je een goed begrip van het verwerken van data met PySpark en begrijp je hoe je Spark’s machine learning-bibliotheek kunt gebruiken om verschillende machine learning-modellen te bouwen.
online of op locatie
R workshops

R is een statistische omgeving en programmeertaal die veel wordt gebruikt door statistici en data scientists om met data te werken. Deze eendaagse workshop zal je gids zijn en je op weg helpen met verschillende programmeeraspecten van R.
Je leert werken met krachtige R technieken en concepten. Je zult je productiviteit verhogen met de meest populaire R-pakketten en datastructuren zoals dataframes, lijsten en matrices. We leren je hoe je vectoren maakt, variabelen afhandelt en andere kernfuncties uitvoert. Je zult data uit verschillende bronnen inlezen.
Vervolgens zullen we meer geavanceerde concepten behandelen, zoals metaprogrammeren met R en functioneel programmeren. Ten slotte krijg je een beeld van R’s mogelijkheden voor datavisualisatie en datamanipulatie.
online of op locatie

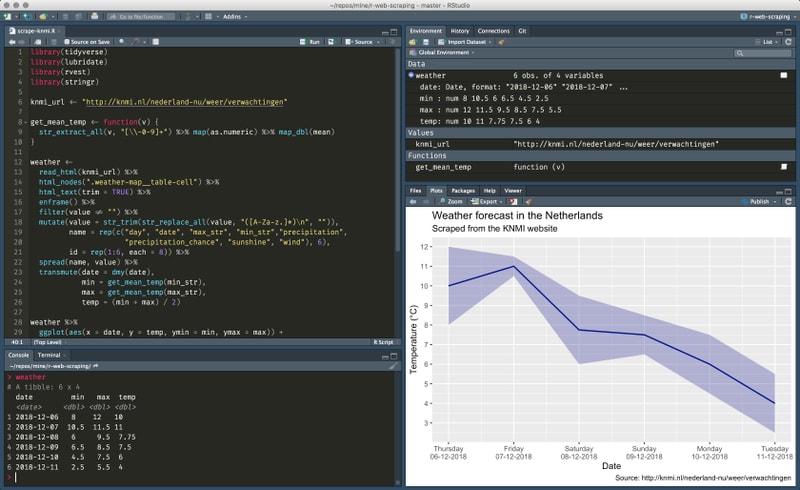
In deze eendaagse hands-on workshop leidt RStudio-gecertificeerde instructeur Jeroen Janssens je door de zogenaamde Tidyverse om data te transformeren. De Tidyverse is een ecosysteem van R-pakketten die een onderliggende ontwerpfilosofie, grammatica en datastructuren delen.
We beginnen bij het begin, met het importeren van CSV-gegevens met readr en spreadsheets met readxl. We zullen de belangrijkste functies van dplyr en tidyr behandelen voor data transformaties en opschoning. We zullen ook kijken naar het omgaan met datums, factoren en tekstuele data, specifiek met behulp van respectievelijk de pakketten lubridate, forcats en stringr. Merk op dat deze workshop ggplot2 niet behandelt; daarvoor raden we onze eendaagse workshop Data Visualisatie met R en ggplot2 aan.
Aan het einde van deze workshop heb je een goed begrip van het Tidyverse ecosysteem en kun je veel van zijn pakketten toepassen op je eigen data.
online of op locatie

In deze eendaagse hands-on workshop gaan we ggplot2, een veelgebruikt R-pakket dat de zogenaamde grammar of graphics implementeert, onder de loep nemen. Dankzij de beknopte en consistente syntaxis kunt je op een snelle en iteratieve manier hoogwaardige datavisualisaties maken die geschikt zijn voor zowel exploratie als communicatie.
Aan het einde van deze workshop heb je een goed begrip van de basisprincipes en je datavisualisaties in R kunt maken voor je dagelijkse werk. Maar let op: de kans is groot dat je meer wilt weten over R.
online of op locatie
Andere populaire workshops
De unix command line, hoewel decennia geleden uitgevonden, is een geweldige omgeving voor het efficient uitvoeren van essentiele data science taken. Door kleine, krachtige tools (zoals parallel, jq en csvkit) te combineren, kun je snel jouw data opschonen en verkennen.
Deze hands-on workshop is gebaseerd op het O’Reilly boek Data Science at the Command Line, geschreven door instructeur Jeroen Janssens. Je leert hoe je snelle data pijplijnen bouwt, hoe je R en Python gebruikt op de command line en hoe je snel data visualiseert. Er is geen voorkennis over unix vereist.
Aan het einde van deze workshop heb je een goed begrip van hoe je de command line kunt integreren in je data science-workflow. Zelfs als je al vertrouwd bent met het verwerken van data met bijvoorbeeld R of Python, zal het kunnen gebruiken van de kracht van de opdrachtregel je een effectievere en efficientere datawetenschapper maken.
online of op locatie

Vraag twaalf mensen wat “data science” betekent, en je krijgt dertien verschillende antwoorden terug. Deze vaagheid gaat helaas gepaard met veel hype en verkeerde verwachtingen. In deze inspiratiesessie willen we dit oplossen door eens goed onder de motorkap van data science te kijken.
In drie uur leggen we niet alleen in heldere bewoordingen uit wat data science inhoudt, maar laten we deelnemers ook ervaren wat een typische data scientist doet door een praktische use case door te werken met behulp van een echte dataset en een programmeertaal zoals Python of R. Deze sessie is bedoeld voor iedereen die wil weten waar data science over gaat (en waarover niet). Zelfs als je nooit van plan bent om zelf met data te werken, kan het een eye-opener zijn om het te hebben meegemaakt. Let op: de kans bestaat dat je daarna meer wilt weten!
online of op locatie

Beschrijving wordt binnenkort toegevoegd.
online of op locatie